
Object Detection: You Only Look Once (YOLO): Unified, Real-Time Object Detection- Summarized
In this post we will discuss about YOLO (You Only Look Once), state of the art deep learning models in object detection. The YOLO model was first described by Joseph Redmon, et al. in the 2015 paper titled YOLO.
What is Object Recognition ?
Object recognition is a general term to describe a collection of computer vision techniques for identifying objects in digital images or videos. Object recognition is a key technology behind driverless cars, enabling to recognize traffic signs or to distinguish a pedestrian from a pillar. It is also usefull in various Bio-Medical fields such as disease identification and also in industrial inspection, and robotic vision.
Object Recognition vs Object Detection
Object detection and object recognition are similar techniques for identifying objects, but they vary in their execution.
- Object Detection: Predict the instance of an object in an image and locate the presence of an object by creating one or more bounding boxes with class label for each bounding box.
In case of deep learning, object detection is a subset of object recognition, where the object is not only identified but also located in an image, This allows for multiple object detection within the image.
Object Detection: Machine Learning Techniques
Machine learning techniques are also popular for object recognition some machine learning techniques are:
- Viola-Jones algorithm
-
First efficient algorithm for face detection was invented by Viola and Jones
-
All human faces share some similar properties. These regularities may be matched using HAAR Features.
-
Rectangular Haar-like features:
value = Σ(pixels in black area) - Σ(pixels in white area)
Three types: two-, three-, four-rectangles. (viola & Jones used two-rectangular features)
-
Two-rectangle feature: Difference between the sum of pixels within two rectangular regions.
-
Three-rectangle feature: Sum within two outside rectangles subtracted from the sum in a center rectangle.


-
Features
-
First feature: The region of the eyes is often darker than the region of the nose and cheeks.
-
Second Feature: The eyes are darker than the bridge of the nose.
-
Support Vector Machines (SVM) were used to classify the images.

-
Limitation: This algorithm was not suitable for tilted faces.
-
-
Histogram of oriented Gradients
-
Introduced by Dallal and Triggs in 2005.
-
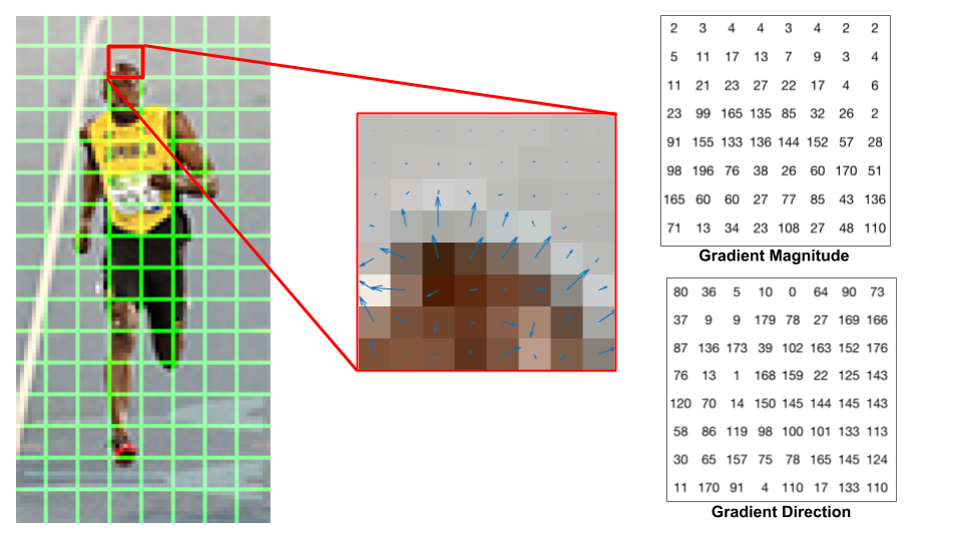
Histogram of oriented Gradients: counts occurences of gradient orientation in localized portions of an image.
-
Image can be described by the *the distributions of intensity gradients or edge directions *
-
For every single pixels, we look at the pixels that directly surrounding it and measures how dark is current pixel compared to surrounding pixels. we will then draw an arrow showing in which direction the image is getting darker.
-
We repeat the process for every single pixel in the image. Each pixel is replaced by an arrow these arrows are called gradients.
-
Gradients shows the flow from light to dark across the entire image.
-
The image is divided into small connected regions called cells, and for the pixels within each cell, a histogram of gradient directions is compiled. Then we will replace that square in the image with the arrow directions that were strongest.

-
Machine Learning workflow:
To perform object recognition using a standard ML approach, we start with the collection of images (or video), and select the relevant features in each image. For example, a feature extraction algorithm might extract edge or corner features that can be used to differentiate between classes in the data. These features are added to a machine learning model, which will separate these features into their distinct categories, and then use this information when analyzing and classifying new objects.
Object Detection: Deep Learning Techniques
Deep Learning techniques have become a popular method for doing object recognition. Deep learning models such as convolutional neural networks, or CNNs, are used to automatically learn an object’s inherent featires in order to identify that object.
For example: a CNN can learn to identify differences between cats and dogs by analyzing thousands of training images and learning the features that make cats and dogs different.
-
Convolutional Neural Networks (CNNs)

There are two approaches to performing object recognition using deep learning:
-
Training a model from scratch: To train a model from scratch, we gather a very large labeled dataset and design a network architecture that will learn the features and build the model. The results can be impressive, but this approach requires a large amount of training data, and we need to set up the layers and weights in the CNN.
-
Using a pretrained deep learning model: Most deeplearning applications use the transfer learning approach, a process that involves fine-tuning a pretrained model. we can use an existing network, such as AlexNet or GoogLeNet and feed in new data containing previously unknown classes. This method is less time-consuming and can provide a faster outcome because the model has already trained on thousands or millions of images.
-
-
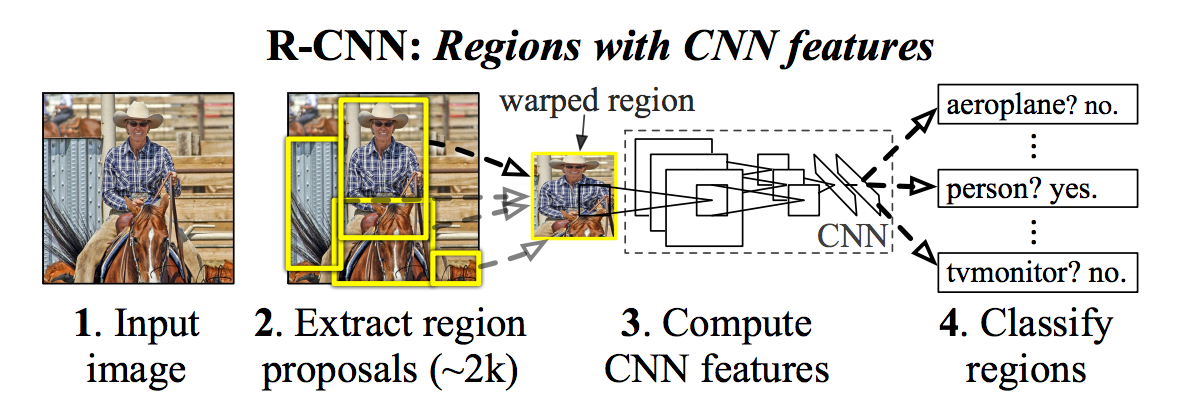
R-CNN: Regions with CNN features
-
Scan the input image for possible objects using an algorithm called Selective search, generating ~2000 region proposals.
-
Run a Convolutional Neural Network (CNN) on top of these region proposals.
- Take the output of each CNN and feed into
- an SVM to classify the region
- a linear regressor to tighten the bounding box of the object, if such an object exists.
- Limitations: R-CNN first generate potential bounding boxes in an image and then run classifier on these proposed boxes. After classification, post-processing is used to refine bounding boxes, eliminate duplicate detections, and rescore the boxes. These complex pipelines are slow and hard to optimize.
-
YOLO: You Only Look Once
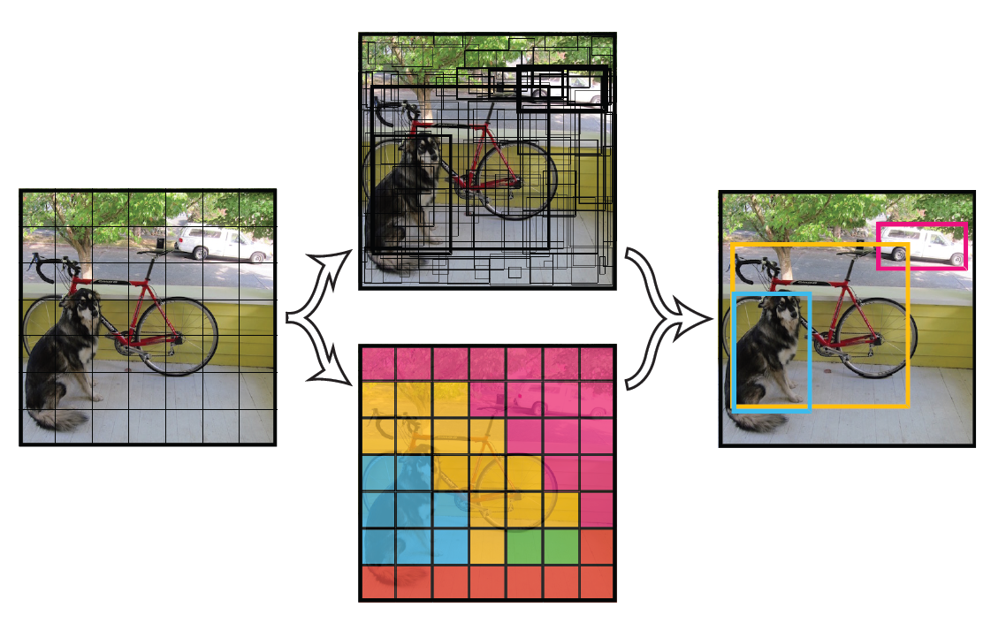
YOLO is a single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation hence the name You Only Look Once.
-
YOLO divides the input image into a grid of SxS of cells.
-
Each of these cells is responsible for predicting 5 bounding boxes: x,y,w, h and confidence.
- (x,y), width , height for the bounding box’s rectangle.
-
confidence prediction represents the IoU between the predicted box and any ground truth box.
Confidence is calculated by: C=Pr(Obj)*IOU
-
The probability distribution over the classes (like dog in an image of 85 %, bycycle of 60%)
Probability is calculated as P=Pr(𝑪𝒍𝒂𝒔𝒔𝒊 Object)
-
Each box of grid predicts N bounding boxes and confidence.
-
The confidence reflects the accuracy of the bounding box and checks whether the bounding box actually contains an object.

As you can observe the fig 7, The higher the confidence score, the fatter the box is drawn.
-
YOLO was trained on the PASCAL VOC dataset, which can detect 20 different classes such as bicycle, boat, car…etc.
-
The confidence score for the bounding box and the class prediction are combined into one final score that tells us the probability that this bounding contains a specific type of object.
-
Total SxSxN boxes will be predicted, but very few boxes will have high confidence. If threshold is 30% we can remove most of boxes.

Network Design

The YOLO network uses standard layer types:
-
Convolution with a 3x3 kernal and a max-pooling with a 2x2 kernal.
-
There is no fully-connected layer in YOLO V2.
-
The very last convolution layer has 1x1 kernal
-
Input image (resized to 416 x 416) grid (SxS, ex: 7x7) for each cell predicts B Bounding boxes( ex: 2), confidence for those boxes and C class probabilities (20 classes). These predictions are encoded as: SxSx(B5+C)* results final prediction 7 x 7x 30 tensor.
Adavantages of YOLO:
-
Speed (45 frames per second)
-
Network understands generalized object representation (This allows them to train the network on real images and predictions are fairly accurate).
Limitations of YOLO
- YOLO struggles with small objects that appear in groups, such as flocks of birds. YOLO struggles to generalize to objects in new or unusual aspect ratios or configurations. It struggles with incorrect localizations.
References
[1] You Only Look Once: Unified, Real-Time Object Detection [2] Gentle Introduction to machine learning by Jason Brownlee [3] YOLO windows and Linux version