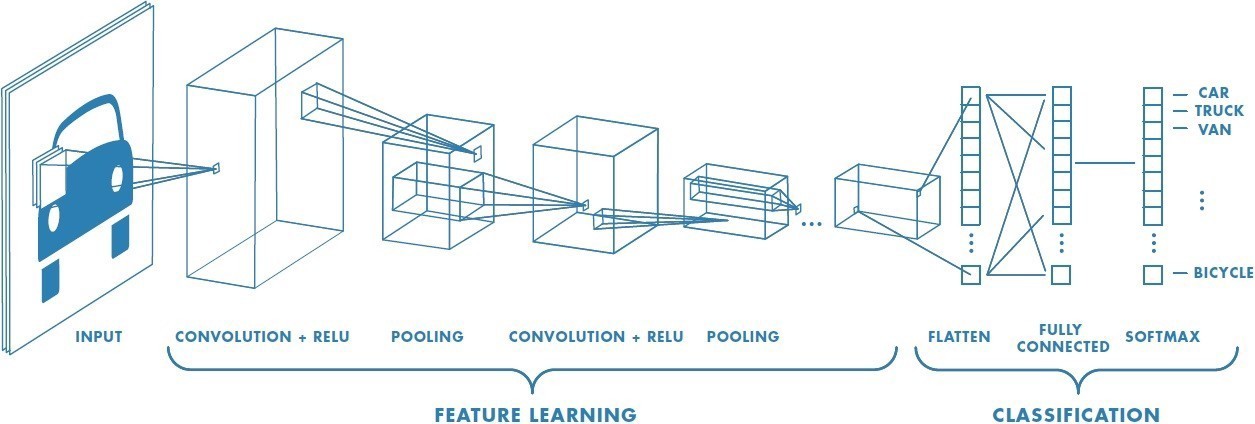

Introduction to Convolutional Network
In this article, we will understand the concepts of Convolutional Neural Networks (CNN’s).
Filters
- Size of Filter: 3x3 or 5x5 (a rule of thumb)
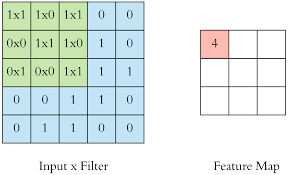
- We take a filter of the size specified by the user (a rule of thumb is 3x3 or 5x5) and we move this across the image from top left to bottom right. For each point on the image, a value is calculated based on the filter using a convolution operation.
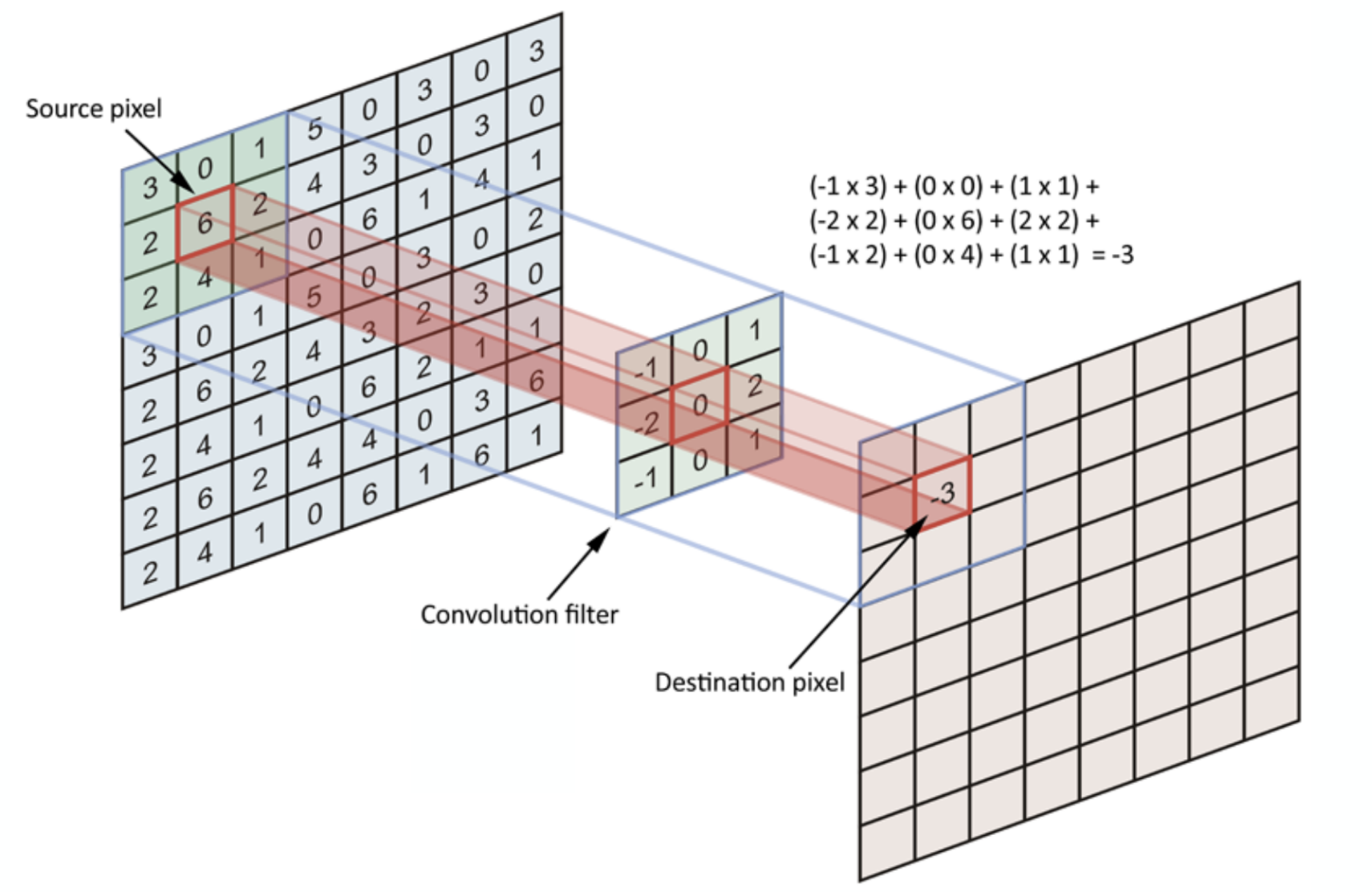
- When building the network, we randomly specify the value for filters, which then continuously update themselves as the network is trained.
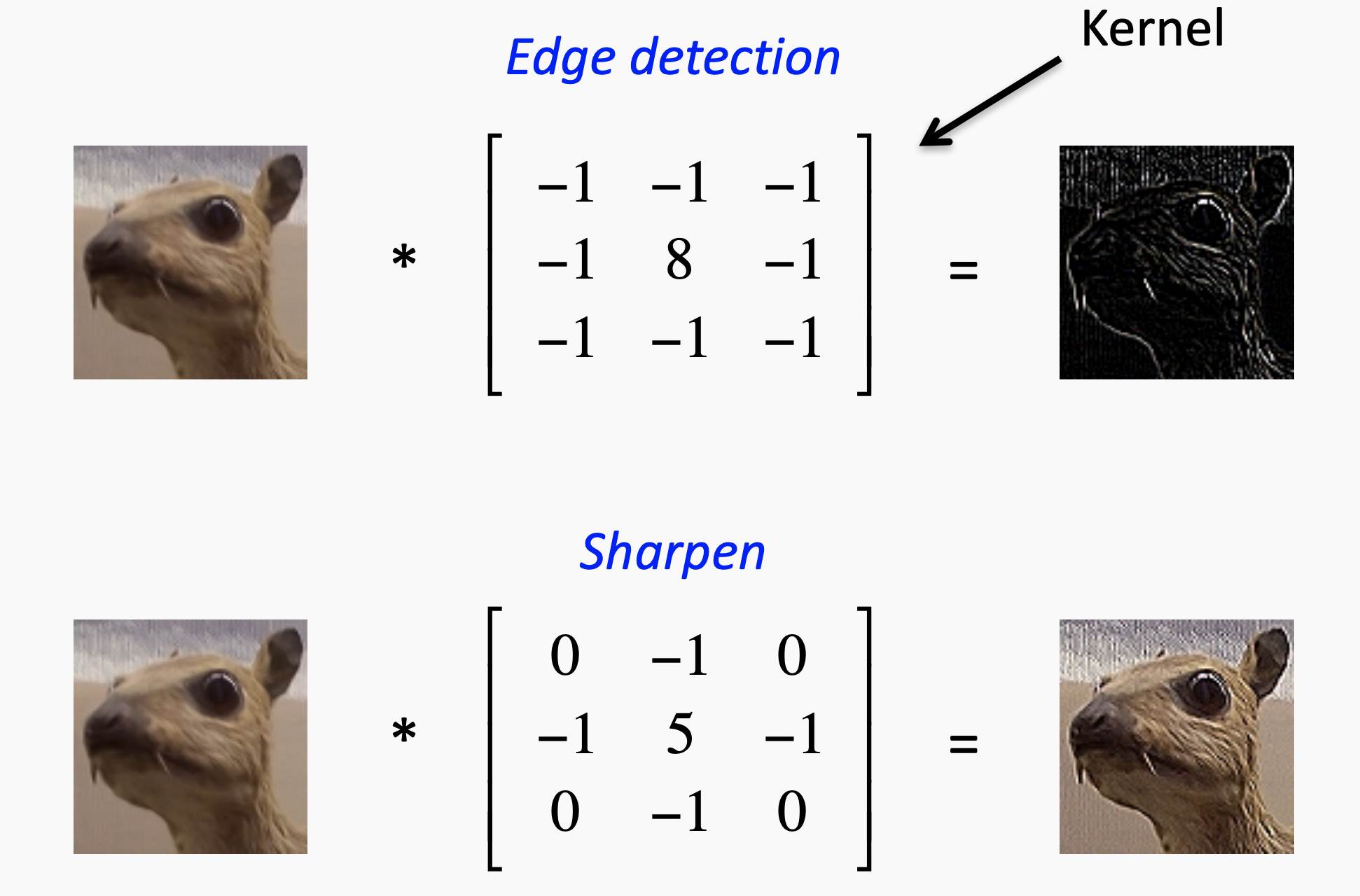
Feature Map
after the filters have passed over the image, a feature map is generated for each filter. These are taken through an activation function.
Pooling (POOL)
The Pooling layer (POOL) is a downsampling operation, typically applied after a convolution layer. we can also use pooling layers in order to select the largest values on the feature maps and use these as inputs to subsequent layers.
In particular, max and average pooling are special kinds of pooling where the maximum and average value is taken.
Max pooling
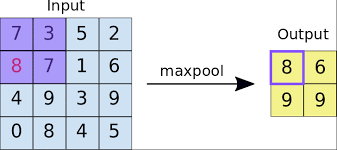
- Each Pooling operation selects the maximum value of the current view.
- Max pooling is used to find outliers, preserves detected features.
Average pooling
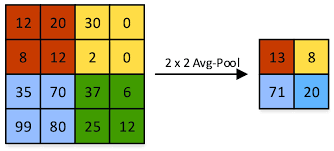
- Each pooling operation averages the values of the current view.
- Ex: Sum (12+20+8+12) resultant value is divided with 4
- Average pooling downsamples the feature map.
Strides
-
For a convolution or a pooling operation, the stride S denotes the number of pixels by which the window moves after each operation.
-
Stride controls how the filter convolves around the input volume.
-
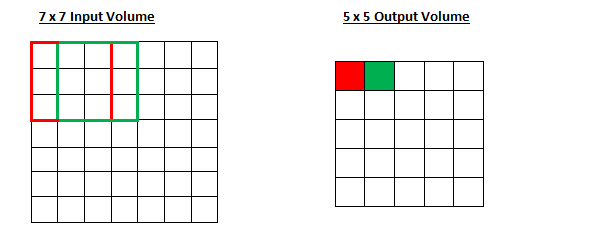
Let’s take 7x7 input volume, a 3x3 filter (Disregard the 3rd dimension for simplicity), and a stride of 1. This is the case that we’re accustomed to.
Padding
Padding essentially makes the feature maps produced by the kernels the same size as the original image.
Why Padding is Important?
-
It is easier to design networks if we preserve the height and width and need not worry too much about tensor dimensions when the transition from one layer to another layer
-
Padding allows for designing deeper networks. without padding, a reduction in volume size would reduce too quickly.
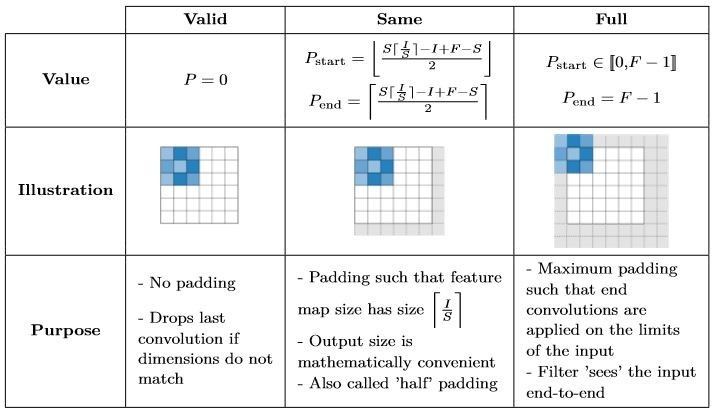
Zero-padding
Zero padding denotes the process of adding P zeros to each side of the boundaries of the input. This value can either be manually specified or automatically set through one of the three modes mentioned below:
Activation layer
After each convolution, it is a convention to apply a non-linear layer( or activation layer) immediately. The purpose of the Activation layer is to introduce nonlinearity to a system that basically computing linear operations during the conv layers( just element-wise multiplications and summations).
Rectified Linear Unit (ReLU)
In the past, nonlinear functions like tanh and sigmoid were used, but researchers found out that ReLU layers work far better because the network is able to train a lot faster (because of computational efficiency) without making a significant difference to the accuracy. it also helps to alleviate the vanishing gradient problem at the lower layers of the network.
ReLU variants are summarized in the table below
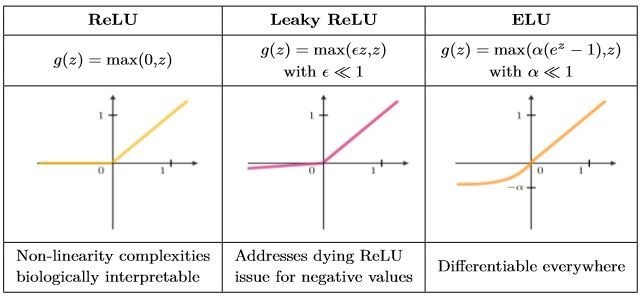
To know more about ReLU
Softmax
Softmax step can be seen as a generalized logistic function that takes as input a vector of scores and outputs a vector of output probability.
softmax produce the likelihoods of an image belonging to a particular class
Dropout
Dropout is used to regularize the fully connected layers within CNN. Dropout layers solve the problem of overfitting, where after training, the weights of the network doesn’t perform well when given new examples. The idea of dropout is simple. this layer “drops out” a random set of activations in that layer by setting them to zero.
finally, the network should be able to provide the right classification or output for a specific example even if some of the activations are dropped out. it makes sure that the network isn’t getting too “fitted” to the training data and thus helps alleviate the overfitting problem.
Fully Connected (FC)
The fully connected layer (FC) operates on a flattened input where each input is connected to all neurons. if present, FC layers are usually found towards the end of CNN architecture and can be used to optimize objectives such as class scores.
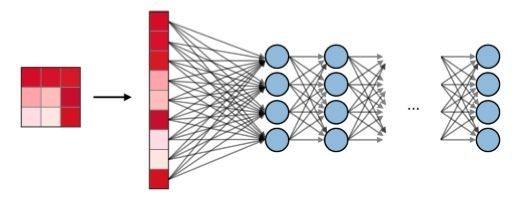
What do CNN layers learn?
-
Each CNN layer learns filters of increasing complexity.
-
The first layers learn basic feature detection filters: Edges, Corners, etc.
-
The middle layers learn filters the detect parts of objects. For face detection, they might learn to respond to eyes, noses, etc.
-
The last layers have higher representations: they learn to recognize full objects, with different shapes, and positions.